Semantic caching stores complete LLM responses in your own infrastructure, keyed by embedding similarity rather than exact text match. When a new query is semantically close enough to one you've already answered, you serve the stored response and skip the LLM call entirely — saving 100% of that call's cost, input and output tokens alike. It is the only caching technique in the LLM caching strategies stack that can take a call to zero.
Here is the honest headline most vendor pages omit: production semantic cache hit rates are 20–45%, not the 90–95% in marketing material. The widely circulated 95% figure traces to match accuracy — how often a served cache hit was the right answer — not to hit rate, the fraction of queries that hit the cache at all. A 30% hit rate at 99% accuracy is a genuinely good production result, and it still cuts roughly a third off the spend on that workload. This post covers the real numbers, the architecture, the similarity thresholds that keep you from serving wrong answers, and the head-to-head comparison with provider-side prompt caching that nobody seems to write down.
LeanLM (not affiliated with Google's LearnLM educational AI) is an LLM cost optimization platform — this post is part of our caching series, focused on semantic response caching specifically.
Definition
Semantic caching is an application-side technique that caches full LLM responses keyed by the embedding of the query that produced them. Incoming queries are embedded and compared against cached entries by vector similarity; if the best match clears a configured threshold, the cached response is returned without calling the LLM. Unlike provider-side prompt caching, it runs in your infrastructure, matches on meaning rather than exact prefixes, and eliminates the entire call on a hit.
How Semantic Caching Works: Architecture and Cost
The pipeline has four stages, and every implementation — GPTCache, Redis LangCache, Portkey's gateway cache, or a homegrown build — follows the same shape (Redis has a good explainer):
- Embed the query. The incoming query is converted to a vector with an embedding model — typically a small, cheap one, since you're matching paraphrases, not doing deep retrieval.
- Vector search. The embedding is compared against the embeddings of previously cached queries, usually by cosine similarity in a vector store.
- Threshold check. If the best match's similarity clears your configured threshold, it counts as a hit.
- Serve or call. On a hit, return the stored response immediately — no LLM call, near-zero latency. On a miss, call the LLM, return the answer, and write the new query–response pair into the cache.
This is real infrastructure you run and pay for: an embedding endpoint, a vector store, and cache storage. The economics still work comfortably. Embedding calls and vector search are orders of magnitude cheaper than LLM generation — in typical deployments the infrastructure costs less than 5% of the savings it generates, even at a modest 10% hit rate. Every point of hit rate above that is margin. To see what an avoided call is actually worth per model, check our effective LLM costs table — on output-heavy workloads, where output tokens bill at 5–6× input rates, a full avoided call is worth far more than any input-side discount.
Semantic Caching vs Prompt Caching
These two get conflated constantly, and they shouldn't be — they operate at different layers, match different things, and fail differently. Prompt caching is a provider-side feature: OpenAI, Anthropic, and Google detect repeated input prefixes (system prompts, tool schemas, shared documents) and bill those cached tokens at roughly 10% of the normal input rate — a 90% discount on the cached portion across OpenAI's GPT-5.x line, Anthropic's lineup, and Gemini 2.5+. But the model still runs, and you still pay full price for every output token. Semantic caching skips the model entirely.
| Dimension | Semantic Caching | Prompt Caching |
|---|---|---|
| What's matched | Meaning of the whole query (embedding similarity) | Exact repeated input prefix (system prompt, tools, context) |
| What's saved on a hit | 100% of the call — all input AND all output tokens | ~90% of the cached input portion only; output billed in full |
| Where it runs | Your infrastructure (embedding model + vector store) | Provider-side; automatic or near-automatic |
| Failure mode | False positive: a wrong cached answer served as correct | Cache miss: you just pay list price — never a wrong answer |
| Typical hit rate | 20–45% of queries (workload-dependent) | Very high on the prefix for any app with a stable system prompt |
| Who should use it | High-repetition, context-free traffic: FAQ, support, search, RAG | Essentially everyone with prompts above the provider's minimum cacheable size |
Prompt-caching discount figures per provider pricing pages, June 2026. They compose: prompt caching cheapens every call your semantic cache misses.
The composition point matters: this is not an either/or decision. Run the semantic cache in front — it eliminates the 20–45% of calls that are repeats. For the 55–80% that fall through, prompt caching discounts the repeated prefix on every one. The two layers attack different parts of the bill and stack cleanly.
Early Access
What Would a Semantic Cache Actually Save You?
LeanLM analyzes your real query traffic, measures its actual repetition rate, and projects your hit rate and savings before you build anything. Join the waitlist below.
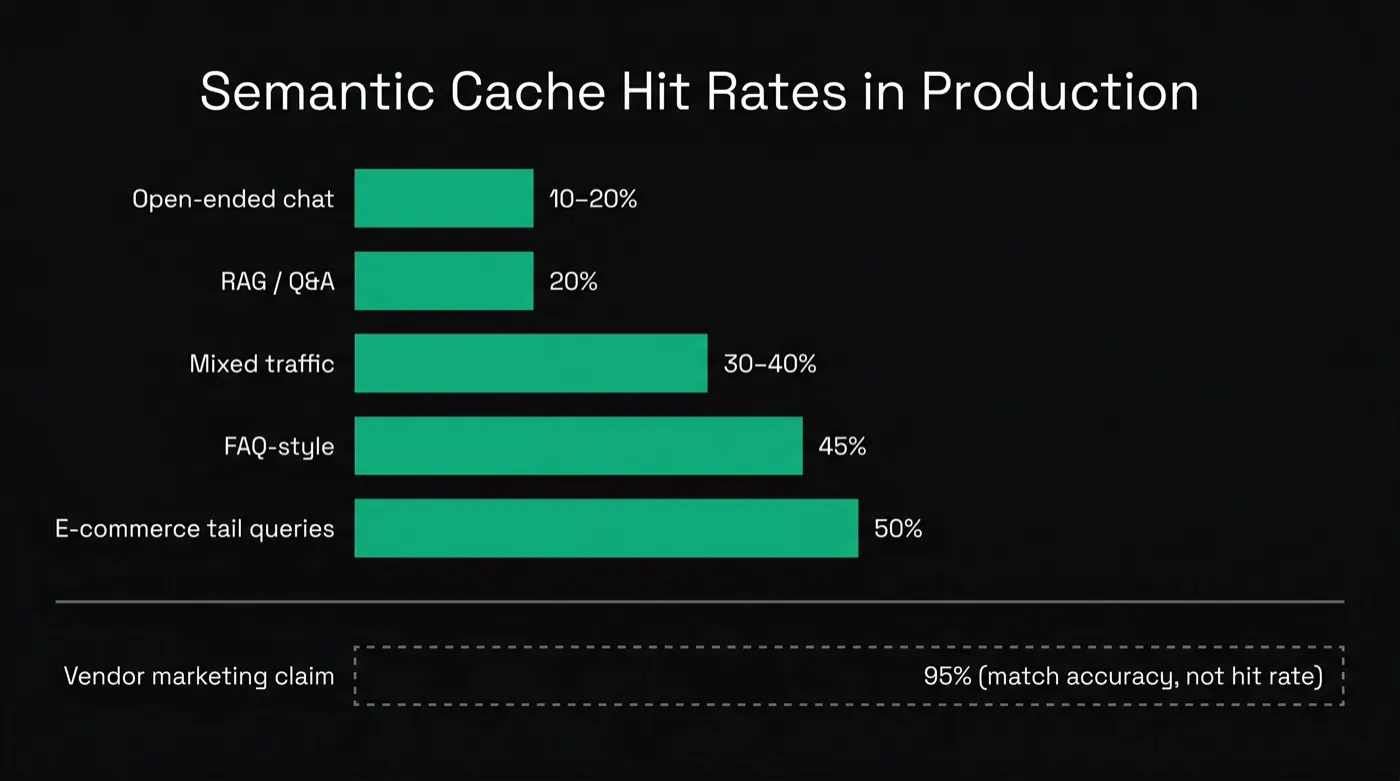
The 95% Hit-Rate Myth: What Production Data Actually Shows
If you've evaluated semantic caching vendors, you've seen "90–95% cache hit rates" in the pitch. Trace those claims to their source and you find a measurement of match accuracy — of the queries that hit the cache, how often the served answer was correct. That's a precision metric. It says nothing about what fraction of your traffic hits the cache in the first place (this production-data writeup documents the conflation in detail).
Here are the production numbers that are actually sourced:
- ~20% hit rate at 99% accuracy — Portkey's gateway data for Q&A and RAG use cases. Twenty percent of calls eliminated, and only 1 in 100 served hits was wrong.
- ~45% hit rate — EdTech FAQ-style workloads, where students ask the same questions in slightly different words all day. This is close to the practical ceiling for most businesses.
- 30–40% hit rate — mixed production traffic combining repetitive and novel queries.
- 10–20% hit rate — open-ended chat, where conversational context makes most queries effectively unique.
- ~50% hit rate on tail e-commerce search queries — Walmart, per Chief Architect Rohit Chatter (Portkey "LLMs in Prod" interview), using cosine similarity on query embeddings. The team expected 10–20% on tail queries and got roughly 50% — an outlier driven by enormous volumes of differently-phrased queries that mean the same thing ("blue running shoes size 10" vs "size 10 blue running shoes").
Two takeaways. First, hit rate is a property of your traffic's repetition structure, not of the caching product — no vendor can give you a number without looking at your queries. Second, 20–45% is excellent. A 30% hit rate means 30% of that workload's LLM bill disappears, at infrastructure cost under 5% of the savings. You don't need the mythical 95% for this to be one of the highest-ROI items in the cost stack.
Similarity Thresholds: 0.85 vs 0.92 vs 0.98
The similarity threshold is the single decision that determines whether your cache is an asset or a liability. Set it too low and the cache returns answers to questions that are similar-looking but materially different — "cancel my subscription" matching "pause my subscription." Set it too high and it degenerates into an exact-match cache that almost never hits.
The working reference points:
- 0.85 — aggressive. Maximizes hit rate on FAQ-style traffic, but carries real false-positive risk. Only defensible where adjacent questions genuinely share an answer and a wrong match is low-stakes.
- 0.92 — the sweet spot. The commonly cited production balance point: catches most true paraphrases while rejecting most near-miss queries that need different answers.
- 0.98 — effectively exact-match. Near-zero false positives, but only trivially rephrased queries hit. You're paying for embedding infrastructure to do what a hash map mostly could.
Portkey's production guidance is the right operational posture: start at 0.95 and tune downward, measuring as you go. The asymmetry justifies the conservatism — a cache miss costs you one LLM call at list price; a false positive costs you a user who received a confidently wrong answer, and in support or commerce contexts, possibly a ticket, a refund, or a trust failure. Serving a wrong cached answer is strictly worse than not caching at all. Tune hit rate and match accuracy as two separate dashboards, and never trade the second for the first.
Early Access
Tune Thresholds on Data, Not Vibes
LeanLM replays your production queries against candidate cache configurations and measures hit rate and false-positive rate at each threshold — before anything ships. Join the waitlist.
When NOT to Use Semantic Caching
Semantic caching has a sharper "don't" list than most cost techniques, because its failure mode is serving wrong answers, not just wasting money:
- Personalized outputs. If the right answer depends on who's asking — account state, order history, user preferences — two identical queries need different answers. Caching across users here isn't a cost optimization, it's a correctness bug (and potentially a data leak).
- Low-repetition traffic. If your queries rarely repeat semantically, the hit rate won't clear the infrastructure cost. Measure repetition on real logs before building — if under ~20% of queries have a near-duplicate, skip it.
- Generative and creative tasks. Users asking for a draft, a variation, or a brainstorm expect novelty. Serving them an identical cached output is a visible product defect, not a saving.
- Agent tool-call loops. Each call inside an agent depends on accumulated session state, so superficially similar queries legitimately require different answers. Agent costs need trajectory-level techniques instead — see our guide to AI agent cost optimization.
One more boundary worth drawing: a semantic cache decides per query whether to skip the model; LLM model routing decides per query which model to call. Both are per-query decisions made in front of the LLM, and they chain naturally — check the cache first, and route only the misses. Cache, route, then let prompt caching discount whatever still reaches a model.
How LeanLM Approaches Semantic Caching
LeanLM treats caching the way it treats every optimization: validate on your data before anything ships. We profile your production query stream to measure its actual semantic repetition, project hit rate per workload segment, replay traffic against candidate thresholds to measure false-positive rates, and only then recommend a configuration — with the accuracy evidence attached. If your traffic won't support a worthwhile hit rate, we'll tell you that too, and point the savings effort at routing, prompt caching, or batching instead.
Frequently Asked Questions
What is a realistic semantic cache hit rate in production?
20–45% for most workloads. Portkey reports ~20% hit rate at 99% accuracy on Q&A/RAG traffic; FAQ-heavy EdTech workloads reach ~45%; mixed traffic lands at 30–40%; open-ended chat drops to 10–20%. Walmart reported ~50% on tail e-commerce search queries — an outlier driven by extreme query-rephrasing volume. The 90–95% figures in vendor marketing refer to match accuracy, not hit rate.
What similarity threshold should I use for a semantic cache?
Start at 0.95 and tune downward while monitoring false positives — this is Portkey's production guidance. As reference points: 0.85 is aggressive (more hits, real risk of serving wrong answers), 0.92 is the commonly cited sweet spot, and 0.98 behaves close to exact-match. Serving a wrong cached answer is worse than a cache miss, so err high.
What is the difference between semantic caching and prompt caching?
Semantic caching stores complete LLM responses in your own infrastructure, keyed by embedding similarity of the query — a hit saves 100% of the call, including all output tokens. Prompt caching is a provider-side feature that discounts repeated input prefixes by roughly 90% (OpenAI GPT-5.x, Anthropic, Gemini 2.5+) but still runs the model and bills full output. They match different things, save different things, and compose — most production systems should use both.
Does semantic caching work for chatbots and AI agents?
Poorly, in most cases. Open-ended chat sees only 10–20% hit rates because conversational context makes queries unique. Agent tool-call loops are worse: each call depends on accumulated state, so semantically similar queries legitimately need different answers. Semantic caching fits high-repetition, context-free workloads — FAQ, support deflection, search, and RAG over stable corpora.