There are three kinds of LLM caching, and they are not interchangeable. Prompt caching (also called prefix caching) reuses the exact token prefix of a request and is billed at 10% of the standard input rate — a 90% discount — at OpenAI, Anthropic, and Google as of June 2026. Semantic caching matches similar queries in your own infrastructure and skips the LLM call entirely, with production hit rates of 20–45%. KV-cache techniques optimize the attention states inside the serving stack and only matter if you host the model yourself.
The economics are no longer marginal. Notion reported that prompt caching reduced its costs by 90% and latency by up to 85% (Anthropic). An OpenAI coding customer lifted its cache hit rate from 60% to 87% with one routing parameter (OpenAI cookbook). And stacked with batch processing, cached input on Claude Sonnet 4.6 drops from $3.00 to $0.15 per million tokens — 95% off list. This guide is the decision framework: what each caching type actually matches, what it saves, and the order in which to deploy them.
LeanLM (not affiliated with Google's LearnLM educational AI) is an LLM cost optimization platform — this guide covers the three caching layers that cut LLM inference cost, and how to choose between them.
Definition
LLM caching is the practice of reusing previously computed work — token prefixes, full responses, or attention states — instead of paying the model to recompute it. It spans three layers: provider-side prompt caching (90% discount on repeated input prefixes), application-side semantic caching (skip the call when a similar query was already answered), and serving-stack KV-cache optimization (reuse attention states across requests when self-hosting).
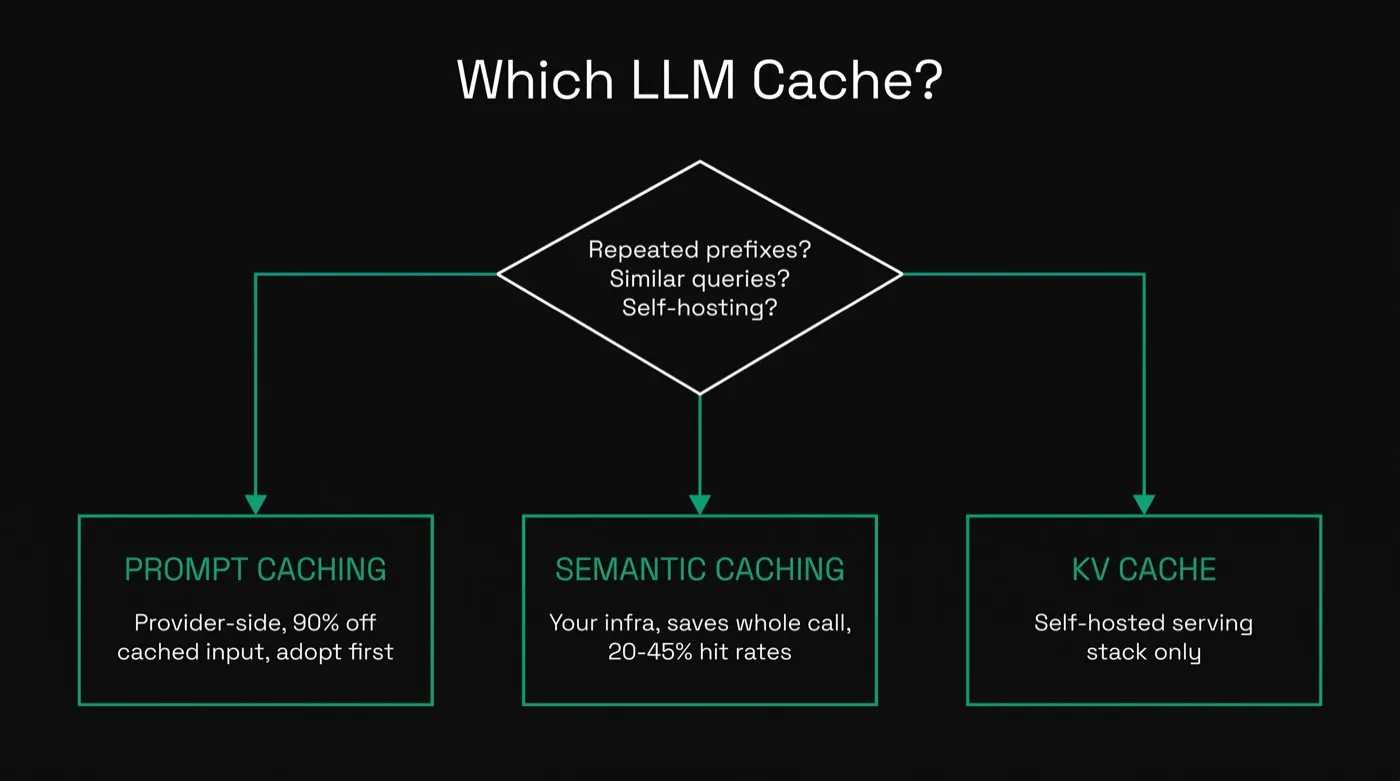
The Three Types of LLM Caching, Compared
Most caching confusion comes from treating these as one technique. They match different things, live in different places, and save money through different mechanics.
| Prompt / prefix caching | Semantic caching | KV-cache techniques | |
|---|---|---|---|
| What's matched | Exact token prefix of the request | Semantic similarity of the query (embedding distance) | Attention key/value states across requests |
| Where it lives | Provider-side (OpenAI, Anthropic, Gemini) | Your infra (embeddings + vector store) | Your serving stack (vLLM, SGLang, TensorRT-LLM) |
| Savings mechanics | Cached input billed at 10% of list (90% off) | LLM call skipped entirely — 100% of the call saved on a hit | Higher GPU throughput / lower latency per request |
| Typical hit rates | High on stable prefixes — 60→87% measured after cache-key routing (OpenAI cookbook) | 20–45% in production; ~20% for RAG/Q&A (Portkey), ~50% on tail queries (Walmart) | Workload-dependent; driven by shared-prefix traffic shape |
| When it applies | Any repeated system prompt, tool schema, document, or conversation history | Repetitive user-facing query traffic (FAQ, search, support) | Only if you self-host open-weight models |
Hit-rate sources: OpenAI Prompt Caching 201 cookbook, Portkey production gateway data, Walmart via Portkey "LLMs in Prod". As of June 2026.
1. Prompt (Prefix) Caching — Provider-Side
When the opening tokens of a request exactly match a recent request, the provider reuses the stored attention states instead of recomputing them, and bills those tokens at 10% of the input rate. It is automatic on OpenAI ("no code changes required") and on Gemini 2.5+ (implicit caching); Anthropic offers both an automatic mode and explicit per-block cache_control breakpoints. The catch is exact-prefix matching: one changed byte early in the prompt invalidates everything after it, which is why prefix-stable prompt structure matters more than any other implementation detail. Full mechanics, minimum token thresholds, and TTL rules are in our dedicated prompt caching deep dive.
Who benefits most: anything with a large stable prefix — long system prompts, tool definitions, shared documents, and multi-turn agents that re-send conversation history every call. Anthropic's own Claude Code is architected around a single hot cache prefix (stable system prompt first, deferred tool loading), with cache reads at roughly 10% of the standard input rate (Anthropic engineering blog). If long shared documents dominate your prompts, pair this with long-context cost management — caching and context strategy compound.
2. Semantic Caching — Your Infrastructure
Semantic caching embeds each incoming query, searches a vector store for previously answered queries above a similarity threshold, and returns the stored response on a hit — the LLM is never called. The savings on a hit are 100% of the call, but hit rates are the honest constraint: production systems see 20–45%, not the 90–95% in vendor marketing (that 95% figure traces to match accuracy, not hit rate). Portkey's gateway data shows ~20% hit rate at 99% accuracy for Q&A/RAG traffic; Walmart measured ~50% on tail search queries against an expected 10–20% (Portkey); open-ended chat is the weakest fit at 10–20%. Threshold tuning is the core engineering problem — 0.85 is aggressive with false-positive risk, ~0.92 is the common sweet spot, 0.98 behaves like exact match; Portkey's guidance is to start at 0.95 and tune down. The full implementation guide is in our semantic caching post.
Who benefits most: high-volume, user-facing, repetitive query traffic — product search, support FAQ, documentation Q&A. Infra cost (embeddings + vector store) typically runs under 5% of the savings even at a 10% hit rate, so the ROI math works at modest hit rates.
3. KV-Cache Techniques — The Serving Stack
Every transformer inference run builds a key/value cache of attention states. Serving frameworks like vLLM (paged attention, automatic prefix caching), SGLang, and TensorRT-LLM exploit this by sharing KV blocks across requests with common prefixes, quantizing the cache to fit more concurrent requests per GPU, and evicting intelligently. This is the layer underneath provider prompt caching — when OpenAI or Anthropic gives you a 90% cached-input discount, KV reuse is what they're passing through. If you call hosted APIs, you cannot touch this layer directly; prompt caching is your interface to it.
Who benefits most: teams self-hosting open-weight models, where serving-stack configuration directly converts shared-prefix traffic into GPU throughput. If that's you, KV-cache work belongs in your capacity planning; if not, skip this layer entirely and spend the effort on prefix-stable prompts.
Early Access
How Much of Your Traffic Is Cacheable?
LeanLM profiles your production LLM traffic, measures your actual prefix-repeat and query-similarity rates, and tells you what each caching layer would save — before you build anything. Join the waitlist below.
LLM Caching Strategies for Cost Reduction: The Decision Framework
The right question isn't "which caching strategy is best" — it's "in what order do I deploy them." The order below is ranked by effort-to-savings ratio, and it holds for almost every workload we've seen.
- Enable prompt caching first — always. It is nearly free to adopt: automatic on OpenAI and Gemini 2.5+, a single
cache_controlparameter on Anthropic. There is no accuracy risk — a prefix either matches exactly or it doesn't — and the discount is 90% on every cached token. There is no scenario where skipping this step is correct. - Restructure prompts to be prefix-stable. Static content first (system prompt, tool schemas, few-shot examples, shared documents), volatile content last (user query, retrieved chunks, timestamps). A timestamp at the top of your system prompt silently zeroes your hit rate. This is also where prompt compression interacts with caching: compress the stable prefix once, and the smaller prefix is what gets cached — but never inject per-request compression artifacts into the prefix, or you'll break the exact match.
- Measure, then route. Read cached-token counts from API responses rather than assuming. If hit rates disappoint at scale, use cache-key routing — OpenAI's
prompt_cache_keytook one coding customer from a 60% to an 87% hit rate by ensuring same-prefix requests land on the same cache (OpenAI cookbook). Caching also cuts time-to-first-token by up to ~80%, so the same fix improves latency. - Add semantic caching only if your traffic is repetitive and user-facing. It requires real infrastructure (embedding pipeline, vector store, threshold tuning, invalidation policy) and carries accuracy risk from false-positive matches. Deploy it when many distinct users ask semantically similar questions — search, support, FAQ — and budget against 20–45% hit rates. Do not deploy it for agent or internal-pipeline traffic, where queries rarely repeat semantically; that traffic is prompt-caching territory, and agents specifically are covered in our AI agent cost optimization guide.
- Do KV-cache work only if you self-host. On hosted APIs this layer is the provider's job. If you run open weights, prefix-aware scheduling and KV-cache quantization in your serving stack are genuine capacity levers — but they are GPU-utilization engineering, not a quick win, and they come after the two layers above.
Prompt caching is a pricing feature you switch on. Semantic caching is a system you build and tune. KV-cache optimization is an infrastructure discipline. Deploy them in that order, and stop at the layer your traffic shape no longer justifies.
Cross-Provider Prompt Caching Snapshot
All three major providers now discount cached input by 90%, but the mechanics differ in ways that change your effective savings. Last verified June 2026 against each provider's pricing and caching docs.
| OpenAI | Anthropic | Google Gemini | |
|---|---|---|---|
| Cached-read discount | 90% on GPT-5.x (75% on gpt-4.1, 50% on gpt-4o) | 90% flat — reads at 0.1× input across models | 90% on Gemini 2.5+ (was 75% on 2.0) |
| Cache-write cost | None | 1.25× input (5-min TTL); 2× input (1-hour TTL) | None for implicit; explicit adds storage ($1.00/MTok/hr Flash, $4.50/MTok/hr Pro) |
| Retention / TTL | ~5–10 min in-memory, up to 1 hr; 24-hour retention default on gpt-5.5+ at no extra fee | 5 min default, 1 hr at the 2× write price; reads refresh the TTL | Implicit: not user-controlled. Explicit: 1-hour default, configurable |
| Minimum cacheable prompt | 1,024 tokens | Per model: 512 (Fable 5), 1,024 (Opus 4.8 / Sonnet 4.6), 4,096 (Haiku 4.5) | 4,096 (3.5 Flash, 3.1 Pro); 2,048 (2.5 Flash/Pro) |
| Automatic vs explicit | Fully automatic; prompt_cache_key for routing |
Automatic mode or explicit breakpoints (max 4) | Implicit automatic on 2.5+; explicit cached_content API for guaranteed hits |
| Example flagship rate (in / cached) | gpt-5.5: $5.00 / $0.50 per MTok | Sonnet 4.6: $3.00 / $0.30 per MTok | gemini-3.5-flash: $1.50 / $0.15 per MTok |
Last verified June 2026 against the OpenAI, Anthropic, and Gemini pricing pages. Two common claims in older posts are now wrong: "OpenAI cached input = 50% off" is GPT-4o-era, and Gemini's implicit-cache discount rose from 75% to 90% on 2.5+. Note the Anthropic write surcharge means caching only pays off when a prefix is read more than once — which is virtually always true in production. Outside the big three, DeepSeek caches automatically with cache-hit input at $0.0028/MTok vs $0.14 on miss (98% off) as of its April 2026 price cut.
One more 2026 shift worth flagging: Gemini's workhorse tier got more expensive — gemini-3.5-flash lists at $1.50/$9.00 per MTok versus $0.30/$2.50 for 2.5-flash — which makes its 90% caching discount proportionally more valuable on the new tier. Cross-provider effective prices with every discount applied are maintained in our effective cost table.
Early Access
Caching Is One Lever. LeanLM Pulls All of Them.
Caching, routing, compression, batching — LeanLM finds which combination cuts your bill the most, and validates it against your production traffic before anything ships. Join the waitlist.
Stacking: Cache × Batch ≈ 5% of List Price
The discounts multiply. Anthropic's pricing page states it directly: caching multipliers "stack with other pricing modifiers, including the Batch API discount." The worked example on Claude Sonnet 4.6 input:
The same stacking now exists, with caveats, at the other two providers. OpenAI supports cached-input pricing inside Batch for GPT-5+ models (earlier models lack caching parity there), and its Flex processing tier offers the same 50% discount with full caching support — the cookbook measured Flex at +8.5 percentage points of cache-hit rate versus equivalent Batch jobs. Gemini publishes discounted batch context-caching rates for explicit caching (3.5 Flash cached input at $0.075/MTok in batch vs $0.15 interactive); whether implicit caching applies inside Gemini batch jobs is undocumented. The full turnaround-time and limits comparison is in our breakdown of LLM batch API economics.
If a workload is non-urgent and shares a heavy prefix — nightly document processing, bulk classification, eval runs — the stacked price is the real price, and list price is a 20× overstatement. That gap is large enough that it should change which workloads you consider economically viable at all. For where caching sits among the other levers — routing, compression, fine-tuning — see our pillar on LLM cost optimization.
How LeanLM Approaches Caching
Caching decisions are traffic-shape decisions, and most teams guess. LeanLM doesn't: a one-line SDK change profiles your production LLM calls, measures actual prefix-repeat rates and query-similarity distributions, and projects what each caching layer would save on your traffic — including the stacked cache×batch price for your batchable share. Semantic-cache candidates are validated for answer accuracy against your real queries before any cached response is served. Savings that don't survive validation don't ship.
Frequently Asked Questions
What is the difference between prompt caching and semantic caching?
Prompt caching matches the exact token prefix of a request and reuses the provider's stored attention states, discounting the matched input tokens by 90% at OpenAI, Anthropic, and Google. Semantic caching runs in your own infrastructure: it embeds incoming queries, finds previously answered queries above a similarity threshold, and returns the stored response — skipping the LLM call entirely. Prompt caching makes repeated calls cheaper; semantic caching eliminates repeated calls.
How much does prompt caching reduce LLM costs?
Cached input tokens are billed at 10% of the standard input rate at all three major providers as of June 2026 — a 90% discount on the cached portion. Real-world impact depends on how much of your traffic is cacheable prefix: Notion reported prompt caching reduced costs by 90% and latency by up to 85%, and an OpenAI coding customer raised its cache hit rate from 60% to 87% by adding prompt_cache_key routing.
What cache hit rate is realistic for semantic caching in production?
Production semantic-cache hit rates run 20–45%, not the 90–95% in vendor marketing (the 95% figure traces to match accuracy, not hit rate). Portkey reports roughly 20% hit rate at 99% accuracy for Q&A and RAG traffic; Walmart measured about 50% on tail search queries versus the 10–20% it expected; open-ended chat is the weakest fit at 10–20%.
Can prompt caching stack with batch API discounts?
Yes. Anthropic states on its pricing page that caching multipliers stack with the Batch API discount: Claude Sonnet 4.6 input at $3 × 0.5 (batch) × 0.1 (cache read) = $0.15 per million tokens, 95% off list. OpenAI supports cached-input pricing inside Batch for GPT-5+ models (Flex processing is the recommended combine path), and Gemini publishes discounted batch context-caching rates for explicit caching.