AI agents cost 5–10× more than equivalent chatbots per task. The reason isn't model pricing — it's that agents make 15–200 LLM calls per task, accumulate context across turns, and silently retry on tool failures. This guide covers the seven cost-blowup patterns that drive production AI agent cost, with real numbers and the specific fixes that work.
The scale is no longer theoretical. Cognition Labs' Devin saved Nubank 8–12× on engineer hours and 20× on cost for a large code migration. Sierra prices AI customer support interactions at $0.25–0.50 each, versus $3–6 for human agents — and resolves 50–70% of contacts autonomously. AI agent cost optimization is the natural next step beyond per-call LLM cost optimization: same techniques apply, but stateful workflow dynamics introduce a whole new set of cost drivers that prompt-level optimization alone won't catch.
LeanLM (not affiliated with Google's LearnLM educational AI) is an LLM cost optimization platform — this post covers cost optimization for production AI agents specifically.
Recent research (Fan et al., 2026 — AgentDiet, arxiv:2509.23586) shows trajectory reduction techniques can cut agent input tokens 39.9–59.7% and total compute cost 21.1–35.9% while maintaining task performance. The cost is addressable — most production teams just haven't audited where it's going.
Definition
AI agent cost optimization is the practice of reducing per-task LLM spend in multi-step agentic workflows by controlling tool-call frequency, context window growth, retry behavior, model tier selection per subtask, and reasoning verbosity. Unlike single-call LLM cost optimization, it addresses the compounding cost dynamics that emerge when an LLM makes many sequenced calls toward a goal.
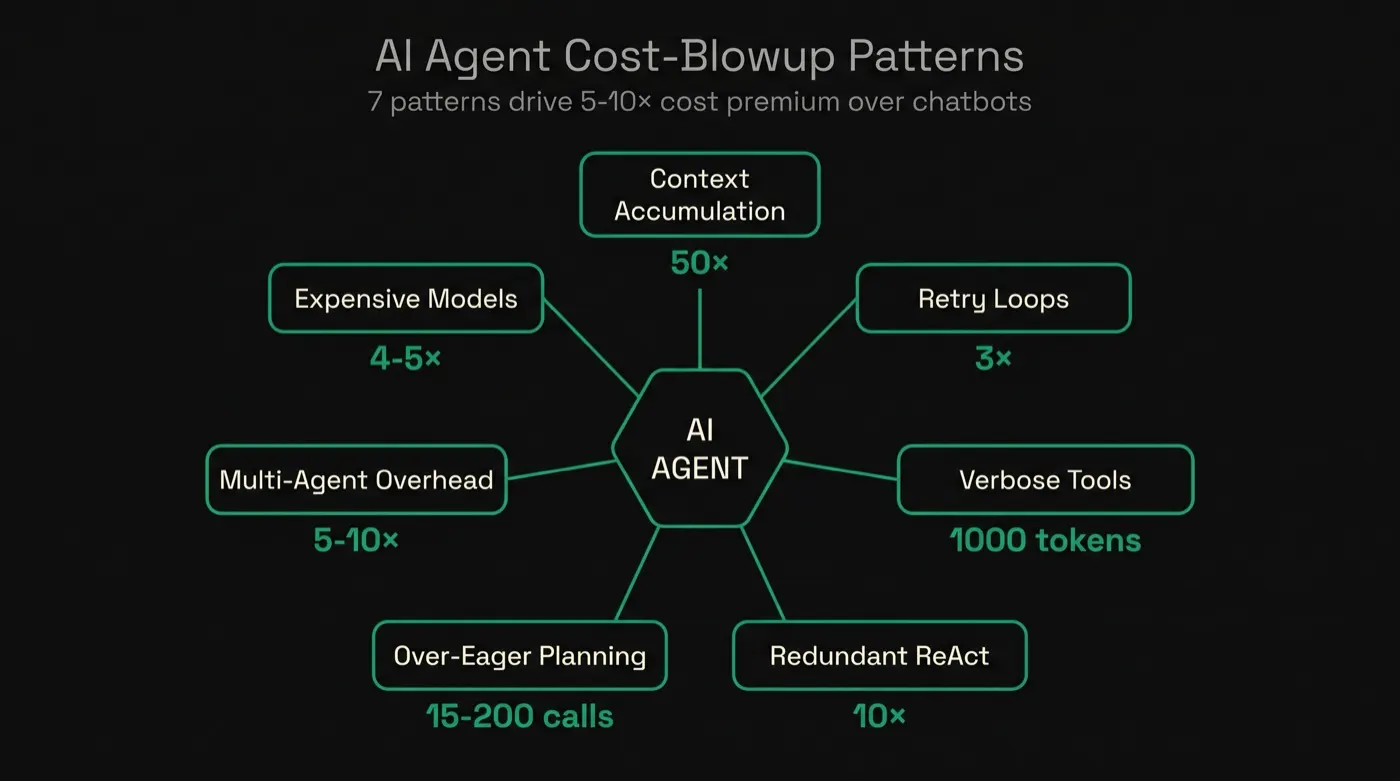
Why AI Agent Cost Optimization Is Different From LLM Cost Optimization
The five classic LLM cost techniques — model routing, semantic caching, distillation, prompt compression, and quantization — still apply to agents. Use them. But they only address the cost of each LLM call. Agents introduce a different layer: the cost dynamics that emerge from making many calls toward a goal, with state carried between them.
An agent's input on call 20 includes the conversation from calls 1–19. An agent's reasoning trace is billed as output tokens. A failed tool call doesn't free the prior context — it triggers another full call to try again. A multi-agent handoff often re-sends most of the working context to the next agent. These dynamics are what blow up agentic AI cost in production, and they're invisible from a single-call cost analysis.
The seven patterns below are the production failure modes. Each one has a typical cost multiplier and a specific fix. The fixes compound: applying all seven typically drops total agent cost by 60–80%.
The 7 Patterns That Blow Up AI Agent Costs
These patterns surface repeatedly across LangChain, LangGraph, CrewAI, AutoGen, and custom agent loops. The order is roughly highest-impact first.
1. Context Accumulation Across Turns
In multi-turn sessions, the full conversation history is re-sent with each LLM call. A 20-turn customer support agent pays for the original query 20 times. A 10-cycle Reflexion loop can consume up to 50× the tokens of a single linear pass — every reasoning iteration adds to the prior context, which is then re-sent on the next iteration.
Typical cost impact: Quadratic token growth over a session. Early messages billed 10–50× depending on session length.
Fix: Apply sliding-window memory, conversation summarization, or token-budget memory (LangChain's ConversationTokenBufferMemory trims older messages automatically). For long contexts, compress the working memory itself with prompt compression techniques — the savings compound on every subsequent turn.
2. Retry Loops on Tool Failures
An AutoGen agent receives an empty search result and retries the same query. A CrewAI agent without max_iter constraints generates 20–30 iterations before timing out, costing $5–8 per run. Failed tool calls don't free the cost — every retry is a full LLM call on the full accumulated context.
Typical cost impact: 3× silent token inflation on unconstrained agents; up to $5–8 per single runaway run.
Fix: Set max_iter aggressively (2–5 for most workflows) and a per-tool max_retry_limit. Add loop detection on near-identical consecutive calls — if the same tool with the same arguments fires twice, halt and surface to a fallback path or human.
3. Verbose Tool Outputs and Overloaded Tool Descriptions
A tool to fetch order status returns 50 database fields when 3 would do. Tool JSON schemas for 5 tools carry roughly 1,000 tokens on every call regardless of which tools the agent actually uses. Both inflate input tokens silently, on every turn, for the life of the session.
Typical cost impact: 200–500 tokens per function-call round trip; ~1,000 tokens of static schema overhead per call with 5 tools loaded.
Fix: Trim tool outputs to required fields at the wrapper layer — not in the LLM prompt. Compress tool descriptions using prompt compression on the schemas themselves. For agents with many tools, use dynamic tool selection so only relevant tool schemas are loaded each turn.
Early Access
Cut Your AI Agent Costs by 40–70%
LeanLM profiles your agent traffic, identifies which of these patterns is driving your spend, and validates fixes on your production data before any change ships. Join the waitlist below.
4. Redundant ReAct Reasoning Steps
ReAct agents generate explicit "Thought:" traces before each action. A complex query might produce 10,000 reasoning tokens before a 200-token final answer. Hidden reasoning tokens in models like o3 and Gemini Thinking compound this — they're billed but invisible in your application's response, making the cost easy to miss until the invoice arrives.
Typical cost impact: Reasoning loops can use 10× the tokens of a direct answer; reasoning-mode models add billable tokens you never see.
Fix: Use constrained output formats (force JSON or short structured responses). For long reasoning traces, apply prompt compression on intermediate trace tokens. When using reasoning models, set explicit reasoning controls (lower effort modes) for subtasks that don't need them.
5. Over-Eager Planning and Unnecessary LLM Calls
A coding agent makes 15–40 LLM calls per task. A deep-research agent makes 80–200. Many are redundant — the agent re-evaluates decisions that prior tool outputs already settled, or it calls the LLM for orchestration steps that pure logic could handle. Every unnecessary call hits the model on the full accumulated context.
Typical cost impact: 3–10× chatbot cost from sheer call volume, before any other pattern kicks in.
Fix: Replace ad-hoc planning with explicit state machines or DAGs for predictable workflows. Route orchestration logic (next-step selection, conditional branching) to cheap models — Haiku, gpt-4o-mini, or Gemini Flash. Reserve frontier models for the genuinely hard reasoning steps.
6. Multi-Agent Communication Overhead
A 3-agent CrewAI workflow (Researcher → Analyst → Writer) re-sends the full working context across each handoff. The Analyst pays for the Researcher's context; the Writer pays for both. Coordination overhead is 20–30% per added agent and exceeds 100% at four or more agents — at which point the "multi-agent" pattern has higher token cost than a single agent making the same calls sequentially.
Typical cost impact: Multi-agent systems are 5–10× single-agent cost. The overhead scales superlinearly with agent count.
Fix: Pass only summarized handoff payloads between agents — not full conversation history. Use shared memory architectures (a common scratchpad) instead of message-passing where possible. Most importantly: question whether multi-agent is needed at all. Many production "multi-agent" systems are sequential single-agent tasks dressed up — and the dressed-up version costs 5× more.
7. Using Expensive Models for Simple Subtasks
An agent calls GPT-4o or Claude Opus for routing decisions, classification, JSON extraction, or template responses — when Haiku 4.5 or Gemini Flash would produce identical results at a fraction of the cost. Flagship models are 4–5× more expensive per token than smaller equivalents, and most agent subtasks don't need flagship reasoning.
Typical cost impact: 4–5× per-token premium on subtasks that don't need it. Most agents have 60–80% of calls in this category.
Fix: Apply LLM model routing inside the agent loop — classify each subtask by complexity and route accordingly. Routing within agents typically captures 40–70% cost savings with no measurable quality loss on the cheap-routed tasks. Pair with LoRA fine-tuning for high-volume task types where a small adapted model can replace API calls entirely.
Production Case Studies
Framework Comparison: LangChain vs LangGraph vs CrewAI
Framework choice affects default cost behavior. The same task on any of these frameworks can cost 10× more or less depending on how you configure context, retries, and model routing — but the defaults matter, especially for teams shipping fast.
| Framework | Default Verbosity | Per-Task Cost (typical) | Built-in Routing | Built-in Caching | Cost Footgun |
|---|---|---|---|---|---|
| LangChain | Verbose | varies; +300–400ms overhead | Via callbacks | LLM cache | Multi-step chains generate many LLM calls; LangSmith subscription separate from LLM cost |
| LangGraph | Lean (O(1) history) | varies; +14ms/query | Manual | Manual | LangSmith Plus $39/user/mo + $0.0036/min standby on Cloud; managed plan can be costly at scale |
| CrewAI | Verbose by default | $0.10–0.20 per 3-agent task on GPT-4o-class models (2025) | Manual | Manual | Unconstrained agents reach $5–8/run; multi-agent overhead compounds quickly |
Framework choice matters less than configuration. The same workflow on any of these can cost 10× more or less depending on max_iter, context strategy, and model routing within the agent. As of June 2026.

Early Access
Comparing Agent Frameworks?
LeanLM benchmarks agent cost across LangChain, LangGraph, CrewAI, and OpenAI Assistants on your actual workload — not on synthetic benchmarks. Join the waitlist to get a personalized cost breakdown when we launch.
Token Economics: Where Agent Cost Actually Goes
Across the agent traffic we and others have profiled, agent cost decomposes roughly as: 60–80% input tokens (driven by context window growth and tool descriptions), 10–20% output tokens (reasoning traces and final answers), and 5–15% tool-call overhead (tool result tokens plus JSON schema overhead on every call).

The input-side dominance is why memory management is the highest-leverage intervention. Cutting reasoning tokens helps, but you're working on the smaller pie. Cutting context accumulation works on the bigger pie — and compounds across every subsequent turn of the session. AgentDiet's 39.9–59.7% input token reduction (Fan et al., 2026) is in this range because it specifically targets accumulated trajectory rather than per-call generation.
This is also why naive prompt-level optimization can disappoint on agents. If you compress a single prompt by 50% but the agent runs 50 turns with re-accumulated context, you've moved a small percentage of the total. Agent cost optimization works at the trajectory level — across the whole session — not just per call.
How to Cut AI Agent Costs Without Hurting Task Success
The order of impact, ranked by what production deployments consistently report as the biggest wins:
- Cap context with sliding-window memory or summarization. Single biggest lever — addresses the input-token majority directly.
- Set
max_iteraggressively. Cheap to ship, prevents runaway agents, easy to roll back. - Route subtasks to cheaper models inside the agent loop. 40–70% savings on subtasks that don't need frontier intelligence.
- Trim tool outputs and descriptions. Especially effective with many tools loaded; compounds with context fix #1.
- Question whether multi-agent is needed at all. Often the right answer is "no" — collapse to a single agent with sequential phases.
"The way to know if a fix is safe is to run the cheaper variant against your actual production traffic and measure task success rate — not benchmark proxies. Most teams skip this step and either ship without confidence or never ship at all."
How LeanLM Approaches AI Agent Cost Optimization
LeanLM applies the validation-first approach to agent traffic specifically. The workflow:
- Profile your agent runs — a one-line SDK change observes every LLM call and tool call in your agent loop, classified by task type and complexity
- Identify cost-driving patterns — surface which of the seven patterns above dominate your traffic (context accumulation? retry loops? expensive-model overuse?)
- Build optimized variants — apply routing, context pruning, retry caps, and tool trimming based on what each agent type needs
- Validate on your data — compare task success rate, latency, and cost on the optimized variant against your production baseline, on your actual queries
- Deploy incrementally — move traffic gradually to the optimized path; revert any subtask where success rate drops
The result: cost cuts that don't ship until they prove they preserve quality on your actual workload. No quality regressions get pushed in the name of savings.
Frequently Asked Questions
Why do AI agents cost so much more than regular LLM calls?
Because agents make many calls per task (15–200), accumulate growing conversation context across turns, generate verbose reasoning traces, and frequently retry on tool failures. A single agent task can use 10–100× more tokens than an equivalent single-shot LLM call. Multi-agent systems compound this further.
How do I calculate the total cost of ownership for an AI agent?
Multiply average token consumption per task (input + output + tool overhead) by your model's per-token rate, then multiply by task volume per month. Add 20–30% overhead per additional agent in a multi-agent system. Don't forget to count retry attempts and aborted runs — they bill the same.
What is context accumulation and why does it blow up my token bill?
In multi-turn agent sessions, the full conversation history is re-sent with each LLM call. A 20-turn session means early messages are paid for 20 times. A 10-cycle Reflexion loop can consume up to 50× the tokens of a single linear pass.
Which AI agent framework is cheapest — LangChain, LangGraph, or CrewAI?
LangGraph is typically the leanest by default due to O(1) conversation history complexity. CrewAI's multi-agent architecture is the most verbose — a 3-agent crew on GPT-4o-class models averages $0.10–0.20 per execution (2025 figures; the pattern holds on the GPT-5.x tier), and unconstrained agents can reach $5–8/run. LangChain falls in the middle but adds ~300–400ms of abstraction overhead. Framework choice matters less than how you configure context, retries, and model selection.
What is a reasonable cost per agent task in production?
Simple chat/RAG agents typically cost under $0.01/task. Customer support agents (multi-turn, tool use) range $0.25–$0.50/task — Sierra publishes this range vs $3–6 for human agents. Deep-research or code agents (Devin-class) range $1–$20/task depending on complexity. Multi-agent systems can be 5–10× single-agent cost.
Does using smaller models in AI agents actually reduce total cost?
Yes — flagship models cost 4–5× more per token than equivalent smaller tiers. Routing simple subtasks (classification, JSON extraction, intent detection) to cheaper models while reserving frontier models for genuinely complex reasoning typically reduces total agent cost by 40–70% with no measurable quality loss on the cheap-routed tasks.
How can I reduce AI agent costs without sacrificing task completion rate?
Set max_iter limits (2-5), prune conversation history with sliding-window memory or summarization, route simple subtasks to cheaper models, trim tool outputs to essentials, and use prompt caching for repeated system prompts. The highest-leverage single intervention is model routing — use a frontier model only on the hardest sub-steps.