Self-hosting an open LLM can drop the raw compute cost per million tokens far below commercial API list prices — but only when the GPU stays busy. At full saturation, an NVIDIA H100 serving a mid-size model costs well under $0.01 per million output tokens of raw GPU time; at 10% utilization that same token costs roughly 10× more, and once you add the engineer(s) to run the cluster, the all-in cost lands around 3–5× the raw GPU bill. The honest break-even: self-hosting beats the API only at sustained, heavy volume — and published estimates of exactly where that point sits disagree by about 50×.
So "is self-hosting cheaper?" is really a utilization question wearing a hardware costume. This guide walks the actual 2026 cost math, the GPU and hardware tiers, the self-host-vs-API break-even, and the honest answer to when it's worth it. It's the build-vs-buy companion to per-call LLM cost optimization — before you optimize an API bill, it's worth knowing whether you should be paying it at all.
LeanLM (not affiliated with Google's LearnLM educational AI) is an LLM cost optimization platform. Note: "LLM" here means Large Language Model — not the Master of Laws degree, which shares the acronym and pollutes a lot of cost searches.
Definition
Self-hosting an LLM means running an open-weight model (such as Llama, Mistral, or Qwen) on your own or rented GPUs behind an inference server (vLLM, TGI, or Ollama), instead of calling a managed API like OpenAI, Anthropic, or Google. You trade a simple per-token bill for a fixed GPU bill plus the engineering to keep it utilized — which is why the economics hinge on how busy you keep the hardware, not on the sticker price of the GPU.
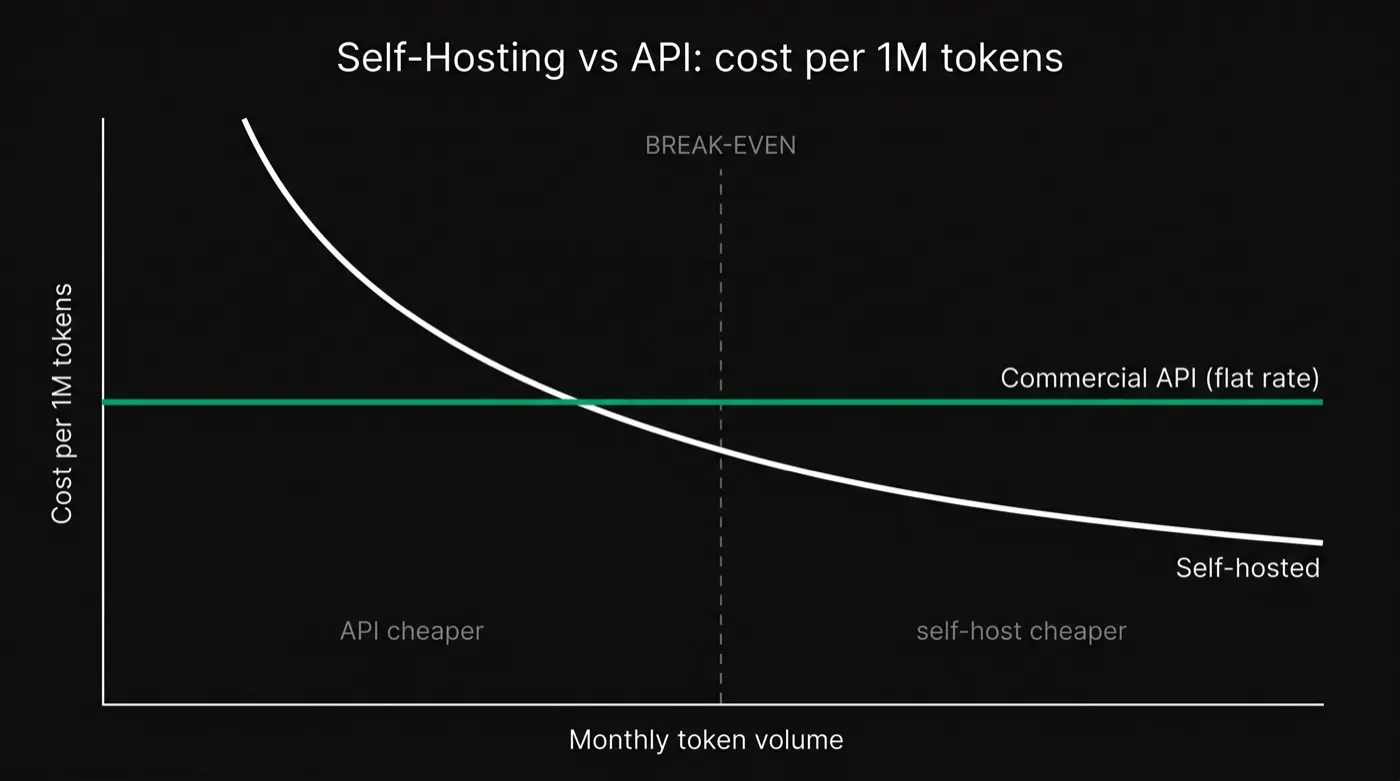
The Real Cost Math: Why Utilization Is Everything
Start with the optimistic number, because it's the one that gets quoted. Take an H100 at roughly $2.50/hr on a specialist GPU cloud, serving a mid-size model at a realistic batched throughput of ~300 output tokens/second. That's about 1.08 million tokens per hour, so the raw GPU cost is on the order of $0.002 per million output tokens at full saturation. Next to GPT-4o at $10 per million output tokens, that looks like a 1000× saving — and that single comparison is how most "just self-host it" arguments are built.
The number is real but the saturation assumption almost never is. A GPU you rent by the hour bills the same whether it's serving 300 tokens/second or zero. Drop from 70% utilization to 10% and your effective cost per token rises roughly 10×. Add the people and process to run production inference — one mid-level MLOps engineer typically covers only 4–6 GPUs, plus monitoring, redundancy, and on-call — and independent total-cost-of-ownership analyses put the all-in number at 3–5× the raw GPU rental. The $0.002 headline can become $0.10–0.13 per million tokens or worse on a half-idle cluster, which is a different conversation entirely.
This is the same lesson as long-context cost management, one level up: the cost you don't see (idle GPU-hours, re-sent context) dwarfs the cost you do. The lever isn't a cheaper GPU — it's keeping the one you have busy.
What GPUs actually cost (mid-2026, on-demand)
| GPU | VRAM | Specialist cloud (~$/GPU-hr) | AWS (~$/GPU-hr) | Best for |
|---|---|---|---|---|
| H100 80GB | 80GB | ~$2–4.30 | ~$6.90 (8-GPU node only) | 70B models; high-throughput serving |
| A100 80GB | 80GB | ~$1.50–2.50 | ~$3.50 | 13–34B models; cost-sensitive serving |
| L40S | 48GB | ~$0.80–1.50 | ~$3.80 | Mid-size models, steady inference |
| L4 | 24GB | ~$0.45–0.80 | ~$0.80 | 7–8B models; cheap, low-concurrency |
| RTX 4090 (buy) | 24GB | ~$2,400 one-time | — | Local/on-prem 7–8B experimentation |
Indicative on-demand ranges as of mid-2026; specialist-cloud (e.g. RunPod, Lambda) prices move week to week — verify on the provider's live page before budgeting. AWS sells H100/A100 only in 8-GPU instances, so the per-GPU figure is arithmetic, not a rentable unit.
Early Access
Not Sure If You Should Self-Host?
LeanLM measures your real token volume and traffic shape, then models self-host vs API cost on your actual workload — so the build-vs-buy call is made on data, not a headline GPU price. Get early access.
GPU and Hardware Requirements: What You Actually Need
Which GPU you need is set by one thing first: whether the model's weights plus its KV cache fit in VRAM. Parameter count and quantization give you the floor; concurrency and context length set the headroom. A rough sizing guide:
| Model size | VRAM (FP16) | VRAM (FP8/INT8) | Fits on |
|---|---|---|---|
| 7–8B (e.g. Llama 3.1 8B) | ~16GB | ~8GB | L4, RTX 4090, A100 |
| 13B | ~26GB | ~13GB | A100 40GB, L40S |
| 34B | ~68GB | ~34GB | A100 80GB, H100 |
| 70B (e.g. Llama 3.1 70B) | ~140GB (2× H100) | ~70–80GB (1× H100) | 1–2× H100 80GB |
Weights only; add KV-cache headroom, which grows with context length and the number of concurrent requests. FP8 quantization is what lets a 70B model fit on a single 80GB H100. As of mid-2026.
Throughput then determines how many requests that GPU can actually serve. On a single H100 with a batched server like vLLM or TGI, an 8B model realistically delivers ~250–400 output tokens/second aggregate, and a 70B model quantized to FP8 lands around ~300–500 tokens/second — both vary several-fold with sequence length, batch size, and engine version, so treat them as a conservative working band rather than a peak. (vLLM's own v0.6.0 release alone delivered ~1.8× throughput over the prior version, so newer stacks are faster.) That tokens/second number, divided into your demand, is your utilization — and utilization is the whole game.
Self-Hosted vs API: The Honest Break-Even
To compare fairly you need the other side of the ledger: current API list prices. As of 2026, per million tokens (input / output):
| Model | Input ($/1M) | Output ($/1M) | Tier |
|---|---|---|---|
| GPT-4o mini | $0.15 | $0.60 | Small / cheap |
| Gemini 2.5 Flash | $0.30 | $2.50 | Small / cheap |
| Claude Haiku 4.5 | $1.00 | $5.00 | Small / cheap |
| Gemini 2.5 Pro | $1.25 | $10.00 | Frontier |
| GPT-4o | $2.50 | $10.00 | Frontier |
| Claude Sonnet 4.6 | $3.00 | $15.00 | Frontier |
List prices as of 2026; confirm against each provider and note the cheap tier is what self-hosting actually competes with. See our LLM effective cost table for cache- and batch-adjusted real prices. Watch the Haiku ambiguity: Haiku 4.5 is $1/$5; the older Haiku 3 was $0.25/$1.25.
Here's where honesty matters more than a tidy chart. Published break-even estimates for self-hosting span roughly 50× — from "more than ~8,000 conversations/day" at one end to "only above hundreds of millions of tokens/day" at the other. That spread isn't sloppiness; it's entirely driven by differing assumptions about utilization and hidden ops cost. The useful framing isn't a single number, it's a tiered rule of thumb that several TCO analyses converge on:
- Under ~$50K/year of LLM spend → use the API. Your volume won't keep a GPU busy, and one engineer to run inference costs more than the bill you're trying to cut.
- ~$50K–$500K/year → go hybrid. Keep most traffic on the API; self-host only your single highest-volume, most predictable task where a fixed GPU genuinely stays saturated.
- Over ~$500K/year of steady volume → a well-utilized GPU cluster (often with LoRA fine-tuning) usually wins — provided you can keep utilization high and staff the ops.
A useful sanity check from inference unit-economics work: a 7B model needs roughly 50% sustained GPU utilization just to beat a cheap hosted model on cost. If you can't confidently project that, the API is almost certainly cheaper all-in. And the target keeps moving — API prices fell on the order of 80% across 2025–2026, which pushes the break-even toward ever-higher volume.
Early Access
Model the Break-Even on Your Workload
LeanLM computes your self-host vs API break-even from your real traffic — utilization, hidden ops cost, and all — and shows whether a hybrid split beats both. Join the waitlist for a personalized breakdown at launch.
When Self-Hosting Is Worth It — and When It Isn't
Cost is only one axis. Self-hosting can be the right call even when it's not strictly cheaper, and the wrong call even when the napkin math looks good.
When self-hosting makes sense
Sustained high volume that keeps GPUs saturated. Data residency or compliance requirements that rule out third-party APIs. Latency or availability control you can't get from a shared endpoint. A fine-tuned or domain-adapted model (often via LoRA adapters) where a small self-hosted model beats a generic frontier API on your task. Predictable, batchable workloads where you can plan capacity tightly.
When the API wins
Low or spiky traffic that leaves GPUs idle — the most common and most expensive mistake. Small teams where MLOps headcount dwarfs the API bill. Rapidly changing model needs where you'd rather swap to the latest frontier model than re-provision hardware. Early-stage products still finding traffic — instrument first, decide later. When in doubt, route to the cheapest capable model on the API before you buy a GPU.
"The fastest way to lose money on AI infrastructure is to buy a GPU before you've measured your traffic. Idle hours don't show up in the benchmark — they show up on the invoice."
Best Self-Hosted Models: SLM vs LLM
The most commonly self-hosted open-weight families in 2026 are Llama 3.x (8B and 70B are the workhorses), Mistral / Mixtral, and Qwen 2.5. But the highest-leverage decision is often size, not family. A small language model (SLM) — Llama 3.2 1B/3B, Phi, or a small Qwen — fits on cheap hardware, serves far more requests per GPU, and frequently matches a frontier model on a specific narrow task while costing a fraction to run.
That's the quiet reason self-hosting sometimes wins: not because an open 70B beats GPT-4o head-to-head, but because you don't need a 70B for classification, extraction, or templated responses. Pair a right-sized SLM with the model-routing instinct — cheapest capable model per task — and the economics improve far more than chasing a lower GPU rate ever will.
How LeanLM Approaches the Build-vs-Buy Decision
LeanLM treats self-host-vs-API as a measurement problem, not a debate:
- Instrument your real traffic — capture monthly input/output tokens and the hour-by-hour load shape, because the traffic pattern decides utilization
- Size the model to hardware — map your model and quantization to the cheapest GPU tier that fits with KV-cache headroom
- Model utilization honestly — divide demand by batched throughput, including idle hours, instead of assuming full saturation
- Load in the hidden costs — apply the 3–5× ops multiplier and any compliance or redundancy overhead
- Compare and recommend — put fully loaded self-host cost next to all-in API price, and surface the hybrid split when it beats both
The output is a number you can take to a budget review: self-host, stay on the API, or run a hybrid — with the break-even shown on your data, not a vendor's.
Frequently Asked Questions
How much does it cost to host your own LLM?
It depends almost entirely on GPU utilization. As of mid-2026, an NVIDIA H100 rents for roughly $2–4/hr on a specialist GPU cloud (around $6.90/GPU-hr on AWS, which only sells 8-GPU nodes). At full saturation that translates to well under $0.01 per million output tokens of raw compute. But a GPU sitting idle still bills the full hourly rate, so at 10% utilization the per-token cost is roughly 10× higher — and once you add the engineering time to run the cluster, the realistic all-in cost is about 3–5× the raw GPU rental.
Is self-hosting an LLM worth it?
For most teams under roughly $50K/year of LLM spend, no — commercial APIs are cheaper and far less work once you count engineering, redundancy, and idle GPU time. Self-hosting starts to win at high, steady volume that keeps GPUs busy (commonly cited thresholds range from about 8,000 conversations/day to hundreds of millions of tokens/day, depending on assumptions), or when data residency, latency control, or a fine-tuned model make it a strategic rather than purely cost decision.
When is self-hosting an LLM cheaper than an API?
Self-hosting is cheaper only when a GPU stays heavily utilized. Below the break-even, the idle hours you pay for erase the per-token advantage. Published break-even estimates vary by roughly 50× because they assume different utilization and ops overhead, so the honest answer is a range: API for low or spiky volume, a hybrid (API plus self-host for the highest-volume task) in the middle, and a well-utilized GPU cluster only for sustained heavy load.
What GPU do you need to self-host an LLM?
It is set by the model's memory footprint. A 7–8B model in FP16 needs roughly 16GB of VRAM and runs on a single L4, RTX 4090, or A100. A 13B model needs about 26GB. A 70B model needs roughly 140GB in FP16 (two H100s) or about 70–80GB quantized to FP8 (a single 80GB H100). Add headroom for the KV cache, which grows with context length and concurrency.
What is the best self-hosted LLM model?
The most widely self-hosted open-weight families in 2026 are Llama 3.x, Mistral/Mixtral, and Qwen 2.5. For narrow tasks, a small language model (SLM) such as Llama 3.2 1B/3B, Phi, or a small Qwen is often the right answer — it fits on cheap hardware, serves more requests per GPU, and matches a frontier model on the specific task while costing a fraction to run.
Does self-hosting an LLM save money for a small team?
Rarely. Small teams usually have variable, bursty traffic that leaves GPUs idle, and a single mid-level MLOps engineer can cost more per year than a large API bill. Commercial APIs also keep cutting prices (roughly 80% over 2025–2026), which pushes the break-even higher. Start on an API, instrument your real token volume and traffic pattern, and revisit self-hosting only when sustained utilization would actually keep a GPU busy.