The hidden cost driver in conversational LLM products isn't the model — it's the protocol. LLM APIs are stateless, so every turn re-sends the entire conversation history as input tokens. That makes an N-turn conversation cost O(N²) in cumulative input: a 50-turn support conversation averaging 300 tokens per turn contains 15,000 tokens of actual dialogue but bills 382,500 cumulative input tokens — a 25× markup. And long context doesn't just cost more in volume; past a threshold it costs more per token: Gemini 3.1 Pro input doubles from $2 to $4 per million tokens above 200k context (Gemini pricing).
Four techniques manage this, in order of how cheaply you should reach for them: prompt caching the stable history prefix (90% off re-sent tokens), summarization checkpoints, pruning, and structured memory. This post works through the math of each and when to apply it — part of our broader guide to LLM caching strategies. For the full stack of techniques beyond context handling, see our LLM cost management guide.
LeanLM (not affiliated with Google's LearnLM educational AI) is an LLM cost optimization platform — this post covers the cost mechanics of long-context and conversation-memory workloads specifically.
Definition
LLM context management is the practice of controlling what portion of accumulated conversation state gets re-sent — and at what price tier — on each model call. Because providers bill input tokens on every request, unmanaged conversation history grows quadratically in cumulative cost. Context management techniques (caching, compaction, pruning, externalized memory) replace "re-send everything at full price" with "re-send less, at 10% of the price, or not at all."
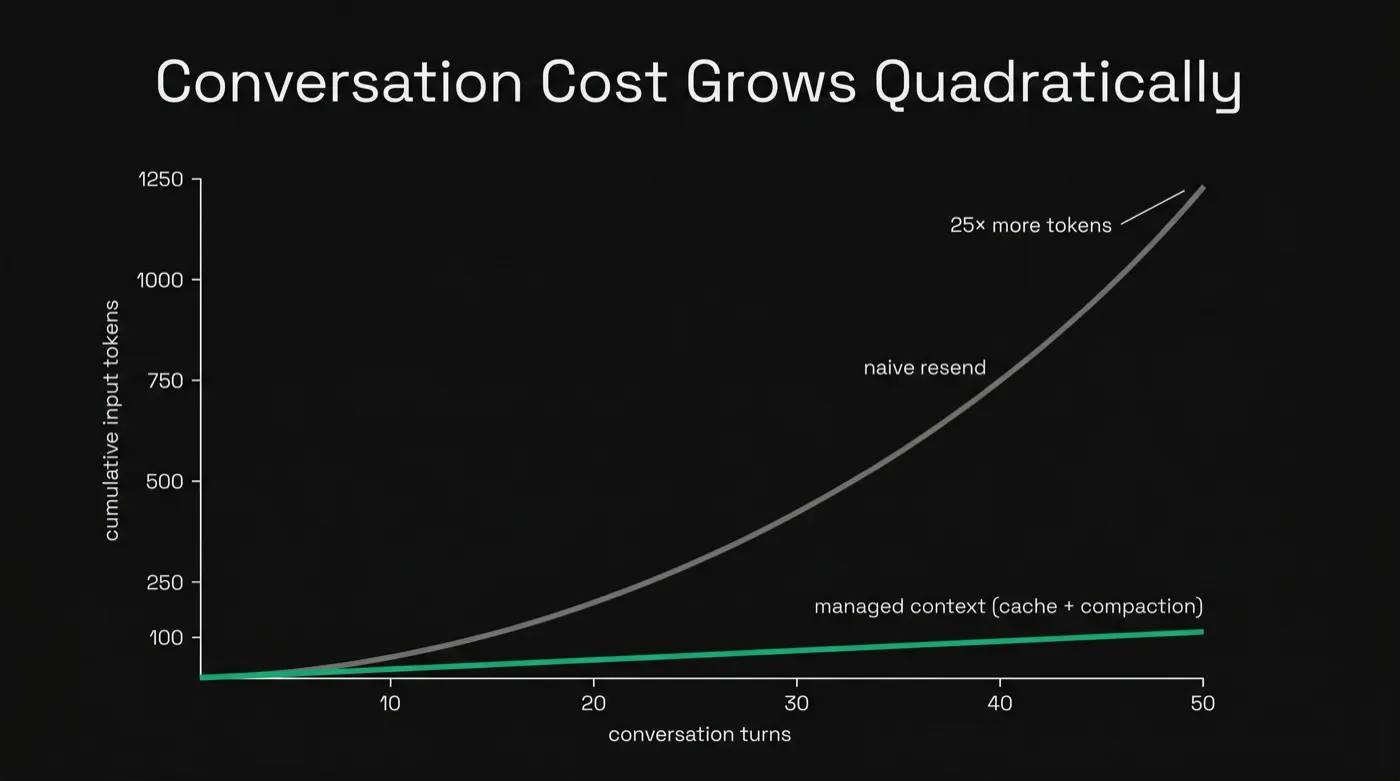
The Math: What a 50-Turn Conversation Actually Bills
Assume a support conversation where each turn (user message plus assistant reply) averages 300 tokens. With naive resend, the input on turn N carries all N−1 prior turns, so cumulative input over the conversation is 300 × N(N+1)/2 — quadratic in turn count. Here's what that bills at gpt-5.5's $5 per million input tokens (OpenAI pricing), with and without its 90% cached-input discount ($0.50/M on the re-sent history, new tokens at full rate):
| Turns | Unique content | Cumulative input (naive) | Markup | Cost @ $5/M | With 90% caching |
|---|---|---|---|---|---|
| 10 | 3,000 tok | 16,500 tok | 5.5× | $0.08 | $0.02 |
| 25 | 7,500 tok | 97,500 tok | 13× | $0.49 | $0.08 |
| 50 | 15,000 tok | 382,500 tok | 25.5× | $1.91 | $0.26 |
| 100 | 30,000 tok | 1,515,000 tok | 50.5× | $7.58 | $0.89 |
Simplified model: 300 tokens per turn, no system prompt or tool schemas (those make it worse — they're re-sent too), cache-write costs excluded. The caching column assumes the history prefix hits cache on every turn. Rates per the OpenAI pricing page, June 2026.
Two things to notice. The markup scales with conversation length — roughly N/2 — so your most engaged users carry the worst unit economics. And even with perfect caching, cost still grows quadratically, just at a 90%-discounted slope. Caching buys an order of magnitude; it doesn't change the shape of the curve. That's why the other three techniques exist.
Why Agents Make It Worse
Everything above assumed 300-token turns of human dialogue. Agents break that assumption in both directions: they take more turns and each turn is heavier. A production agent makes 15–200 LLM calls per task, and every tool result — search output, database rows, file contents — lands in the context and gets re-sent on every subsequent call. A 20-turn agent session pays for its original query 20 times, and a 10-cycle Reflexion loop can consume up to 50× the tokens of a single linear pass, as we covered in our guide to AI agent cost optimization.
The research backs up how much of this is waste: trajectory-reduction techniques cut agent input tokens by 39.9–59.7% while maintaining task performance (Fan et al., 2026 — AgentDiet, arxiv:2509.23586). If half your agent's accumulated context can be deleted without hurting outcomes, you were paying to re-send stale tokens on every call. Context management isn't an agent-specific discipline — but agents are where ignoring it gets expensive fastest.
The Four Context Management Techniques
In the order you should deploy them: cheapest and safest first.
1. Prompt Caching the Stable Prefix
Conversation history is the ideal caching workload: an append-only prefix that's identical between consecutive requests. All three major providers bill cached input at 10% of the standard rate — a 90% discount on OpenAI GPT-5.x, all current Anthropic models, and Gemini 2.5+ (see our prompt caching deep dive for full mechanics). Applied to the 50-turn example: $1.91 drops to roughly $0.26 — an 86% cut from one configuration change. Notion reported prompt caching reduced costs by 90% and latency by up to 85%.
Cost mechanics: OpenAI caches automatically with no write surcharge, and gpt-5.5+ gets extended cache retention up to 24 hours by default at no extra fee — long enough to survive a user who replies the next morning. Anthropic charges a cache-write premium (1.25× input for the 5-minute TTL, 2× for 1-hour) but reads refresh the 5-minute TTL, so an active conversation stays warm indefinitely without re-paying the write. Gemini caches implicitly on 2.5+ models, with an explicit cached_content API (storage billed at $4.50/MTok/hr on Pro) for guaranteed hits.
Fix: Keep the prefix byte-stable — system prompt first, tool definitions fixed, history strictly append-only. Any edit to an earlier message invalidates everything after it. This is exactly how Anthropic architected Claude Code: one hot cache prefix, append-only context, with cache reads billed at roughly 10% of the standard input rate.
2. Summarization / Compaction Checkpoints
Compaction spends output tokens once to shrink input tokens forever after: summarize the history into a short checkpoint and continue the conversation from the summary. On gpt-5.5, compacting a 10,000-token history into a 500-token summary costs about $0.065 (one 10k input pass at $5/M plus 500 output tokens at $30/M) and removes 9,500 tokens from every subsequent request — $0.0475 per turn saved at full input rates. Payback: about 2 turns.
The catch: compaction rewrites the prefix, which invalidates the prompt cache. Against an already-cached history, the per-turn saving falls to $0.00475 and payback stretches to ~14 turns. So compaction and caching are complements with a sequencing rule, not substitutes: cache continuously, compact at discrete thresholds (history size, tier boundaries, session handoffs), then let the new shorter prefix re-warm.
Fix: Trigger compaction when history crosses a token threshold rather than every turn. Preserve verbatim what the summary can't safely paraphrase: IDs, constraints, user-stated requirements. For squeezing more out of what remains in context, prompt compression techniques stack on top.
Early Access
How Much of Your Bill Is Re-Sent History?
LeanLM profiles your production traffic, measures what fraction of input spend is redundant context, and validates caching and compaction fixes against your real conversations before anything ships. Join the waitlist below.
3. Pruning and Trimming
Pruning simply stops re-sending turns that no longer matter. A sliding window keeps only the last K turns, capping per-request input at K × turn-size and turning O(N²) cumulative growth into O(N·K). On the 50-turn example, a 10-turn window cuts cumulative input from 382,500 to 136,500 tokens — about 64% — before caching is even applied.
Cost mechanics: Unlike compaction, pruning costs nothing to perform — no summarization pass, no output tokens. The price is information loss: anything outside the window is simply gone. Relevance filtering is the smarter variant — score prior turns against the current query and include only what's pertinent — at the cost of an embedding or scoring step.
Fix: Sliding windows fit chat workloads where old turns rarely matter (casual assistants, transactional support). Pin must-keep content (system prompt, user profile, stated constraints) outside the window so it survives trimming — and keep the pinned block first and stable so it stays cacheable.
4. Structured Memory
The other three techniques manage what's in the context window. Structured memory moves state out of it: durable facts (user preferences, account state, task progress, prior decisions) live in an external store — key-value, database rows, or a vector index — and each turn retrieves only the handful of entries it actually needs. Per-turn input stops growing with conversation length and becomes roughly constant: recent turns plus a small retrieved slice.
Cost mechanics: You trade quadratic token growth for retrieval infrastructure that's cheap by comparison — for the related case of caching repeated answers, embedding-plus-vector-store overhead typically runs under 5% of the savings. The same retrieval machinery powers semantic caching, which solves the cross-user version of this problem: recognizing when a new conversation is asking a question you've already paid to answer.
Fix: Best fit for agents and long-lived assistants, where state must survive sessions anyway. Write facts to memory as they're established, retrieve by relevance at each turn, and keep the retrieved slice small and positioned after the stable prefix so it doesn't thrash the cache.
Which Technique When
The decision order is about risk-adjusted return, and the ranking is unusually clean:
- Caching first — always. It's the free win: 90% off re-sent history with zero quality risk, automatic on OpenAI and Gemini, a few breakpoint annotations on Anthropic. There is no workload where leaving conversation history uncached is correct.
- Compaction at thresholds. When histories regularly exceed ~10–20k tokens, checkpoint-summarize. Schedule it where it's cheapest: before a pricing-tier boundary, at session handoffs, or when the cache has gone cold anyway.
- Pruning for chat. Where cross-turn dependency is low, a sliding window plus pinned essentials captures most of compaction's benefit with none of its summarization cost or hallucination risk.
- Structured memory for agents. Long-lived, tool-using, stateful workloads justify the engineering. It's the only technique that makes per-turn cost independent of conversation length.
"Teams debate summarization strategies for weeks while running uncached. Get the 90% discount on day one, then use real cache-hit data to decide whether you need anything more sophisticated."
The 200k Tier Trap
There's a second, sneakier long-context cost beyond volume: tiered pricing. On Gemini 3.1 Pro, requests above 200k tokens of context bill input at $4/M instead of $2/M, output at $18/M instead of $12/M — and even cached tokens double, from $0.20 to $0.40 per million (Gemini pricing). Cross the boundary and the entire request bills at the higher tier, not just the overflow. A conversation that drifts past 200k tokens doesn't get 1% more expensive — its rate doubles.
The general principle: stuffing the context window is the most expensive form of memory. Every stale token is billed on every turn, pushes you toward premium tiers, and degrades retrieval quality as the model attends over more irrelevant material. If your sessions approach 200k tokens, a compaction checkpoint just before the boundary literally halves your input rate. Treat the context window as hot cache, not as the database.
Early Access
Running Conversations Near the Tier Boundary?
LeanLM finds where your sessions cross pricing tiers and which compaction or pruning checkpoint pays back fastest — measured on your actual conversation traffic, not synthetic benchmarks. Join the waitlist.
How LeanLM Approaches Long-Context Costs
LeanLM applies its validation-first workflow to context spend:
- Profile your traffic — a one-line SDK change measures, per conversation, how much input is re-sent history versus new content, and what your actual cache hit rate is
- Quantify the waste — surface the cumulative-input multiplier for your real turn distributions, not a synthetic benchmark
- Build managed variants — caching configuration, compaction thresholds, window sizes, and memory schemas tuned to your workload
- Validate on your data — replay real conversations through the managed variant and compare answer quality, latency, and cost against your production baseline
- Deploy incrementally — shift traffic gradually; revert any segment where quality drops
The result: context-management savings that prove they preserve quality on your actual conversations before they ship.
Frequently Asked Questions
Why does a long conversation cost so much more than a short one?
LLM APIs are stateless, so every turn re-sends the entire conversation history as input tokens. An N-turn conversation therefore bills O(N²) cumulative input. A 50-turn conversation at 300 tokens per turn contains 15,000 tokens of actual content but bills 382,500 cumulative input tokens — a 25× markup. At 100 turns the markup is 50×. Cost grows with the square of conversation length, not linearly.
How much does prompt caching cut long-conversation costs?
Cached input is billed at 10% of the standard rate — a 90% discount — on OpenAI GPT-5.x, all current Anthropic models, and Gemini 2.5+. Since the re-sent history is exactly a stable, growing prefix, it caches almost perfectly: the worked 50-turn example drops from $1.91 to about $0.26, an 86% reduction. Notion reported prompt caching cut costs 90% and latency up to 85%.
Should I summarize the conversation history or just cache it?
Cache first — it's nearly free and has zero quality risk. Summarization (compaction) trades output tokens now for smaller input on every future turn, but it rewrites the history, which invalidates the cached prefix. Compacting a 10,000-token history into 500 tokens costs about $0.065 on gpt-5.5 and pays for itself in roughly 2 turns uncached — but about 14 turns if the history was already cached. Use compaction as a checkpoint when history crosses a size threshold, then let the new, shorter prefix re-warm the cache.
Does pricing change above 200k tokens of context?
On Gemini 3.1 Pro, yes: input doubles from $2 to $4 per million tokens above 200k context, output rises from $12 to $18, and even the cached-token rate doubles from $0.20 to $0.40. Crossing the 200k boundary means every token in the request — not just the overflow — bills at the higher tier. If your conversations approach 200k tokens, compaction or pruning before the boundary directly halves the input rate.